参考博客
http://www.mamicode.com/info-detail-1792965.html
https://www.cnblogs.com/xuzekun/p/7527736.html
https://blog.51cto.com/linux5588/1351007
一次http请求过程概览
对URL进行DNS域名解析,解析到对应的IP地址;
client根据ip地址,向对应服务器发起tcp三次握手连接;
建立tcp连接后,client发起http请求;
服务器响应http请求(返回状态码),client获取到html代码;
client解析index.html的代码,并请求html中的资源(js,css等);
浏览器渲染页面并显示。
具体细节
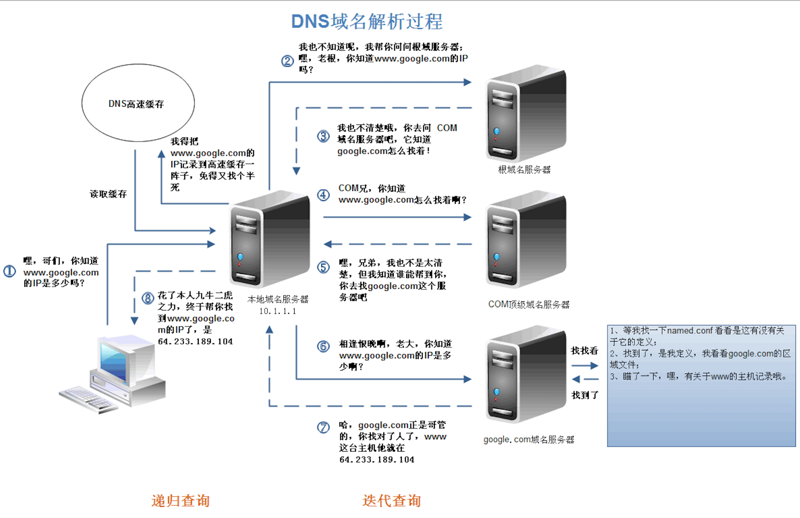
1、域名解析
① 浏览器首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存),看自身的缓存中是否有URL对应的条目,而且没有过期,如果有且没有过期则解析到此结束;
② 若未找到,则搜索系统的DNS缓存;
③ 若仍未找到,则检查本地host文件是否存在该网址映射关系
④ 如果都没有则递归地去域名服务器去查找,如下图
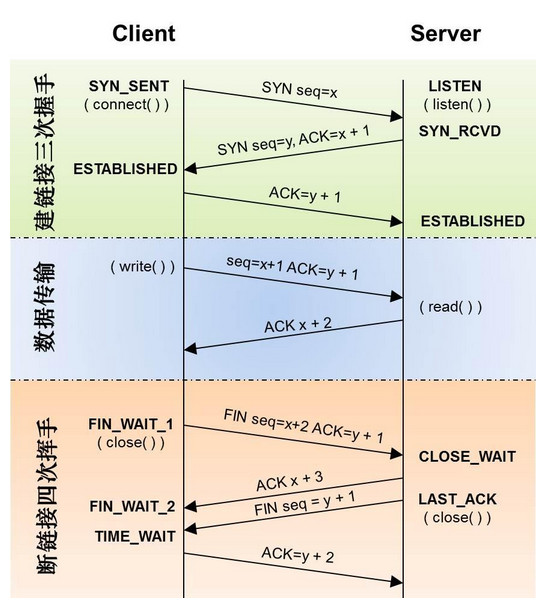
2、建立TCP连接,三次握手
获取到域名对应的ip地址之后,浏览器以某一个随机端口向服务器WEB程序的80端口发起TCP连接请求。详见TCP三次握手与四次挥手
3、发起http请求
HTTP请求报文包括三部分:请求行,请求头和请求正文
【请求行】请求方法 空格 请求资源地址(URI、无域名) 空格 HTTP版本 空格 CRLF(换行符)
【请求头】标识:内容 CRLF(换行符)
【空一行】(表示请求头结束)
【请求主体】(即请求正文,用户的主要数据。POST方式时使用,GET无请求主体。GET方式是保存在url地址后面,不会放到这里)
get请求报文举例
1 | GET /java/ HTTP/1.0 (请求行) |
post请求报文举例
1 | POST http://oa.funds.com.cn:9080/ HTTP/1.1 (请求行) |
请求头 Connection,Connection设置为keep-alive用于说明客户端这边设置的是,本次HTTP请求之后并不需要关闭TCP连接,这样可以使下次HTTP请求使用相同的TCP通道,节省TCP建立连接的时间
4、服务器响应http请求,浏览器获得html代码
HTTP响应报文也包括三部分: 响应行,响应头,响应主体(也可以叫 状态行,消息报头,响应正文)
【状态行】HTTP版本 空格 状态码 空格 状态码描述 空格 CRLF(换行符)
【响应报文头】标识:内容 CRLF(换行符)
【空一行】(表示响应头结束)
【响应主体】(所谓响应主体,就是服务器返回的资源的内容。即整个HTML文件)
post响应报文举例
1 | HTTP/1.1 200 OK (状态行) |
get响应报文与post请求方式结果基本相同,不再赘述。
服务器端接收到http请求后如何生成html文件此处也不赘述
- 常见状态码及其描述
1xx: 指示信息——表示请求已接收,继续处理
2xx: 成功——表示请求已被成功接收、理解、接受
3xx: 重定向——要完成请求必须进行更进一步的操作
4xx: 客户端错误——请求有语法错误或请求无法实现
5xx: 服务器端错误——服务器未能实现合法的请求
200 OK : 客户端请求成功
400 Bad Request:客户端请求语法错误,服务器无法解析
401 Unauthorized:请求未经授权
403 Forbidden:服务器收到请求拒绝服务
404 Not Found:请求资源不存在,常见URL错误
500 Internal Server Error:服务端不可预期错误
503 Server Unavailable:服务器当前不能处理客户端请求
5、浏览器解析html,请求html中的资源
浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源,下载资源的顺序就是按照代码里的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源,所以从下图看出,这里显示的顺序并不一定是代码里面的顺序。
6、浏览器渲染页面,显示
在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了,具体如何渲染涉及到前端和浏览器内容,此处不赘述。