正则表达式
https://www.runoob.com/regexp/regexp-tutorial.html
字符串拼接性能 & StringBuffer与StringBuilder
参考博客
https://www.cnblogs.com/lojun/articles/9664794.html
https://blog.csdn.net/u014086926/article/details/52069074
字符串拼接性能
在大部分情况下 StringBuilder > StringBuffer > String
相当于 不加锁>加锁>创建新对象
用+的方式效率最差,concat由于是String内部方法,性能优于+M的方式:str.concat(“new str”);
单线程下字符串的串联用StringBuilder的append,多线程下字符串的串联用StrngBuffer的append;
字符串的加号“+” 方法,虽然编译器对其做了优化,使用StringBuilder的append方法进行追加,但是每循环一次都会创建一个StringBuilder对象,且都会调用toString方法转换成字符串,所以开销很大
在编译阶段就能够确定的字符串常量,完全没有必要创建String或StringBuffer对象。直接使用字符串常量的”+”连接操作效率最高(如:String str = “a” + “b” + “c”;)
举例说明:
单个String对象的字符串拼接在编译阶段被 JVM 解释成了StringBuilder虽然也被对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢,而特别是以下的字符串对象生成中,String 效率是远要比 StringBuffer 快的:
1 | String S1 = “This is only a” + “ simple” + “ test”;//快 |
原因是JVM将
1
String S1 = “This is only a” + “ simple” + “test”;
等同于了
1 | String S1 = “This is only a simple test”; |
所以当然不需要太多的时间了。但如果字符串是来自另外的 String 对象的话,速度就没那么快了,譬如:
1 | String S2 = “This is only a”; |
这时候 JVM 会按照原始的方式,疯狂创建对象并连接。
StringBuffer与StringBuilder
String对象是不可变的,修改String时重新指向另一个对象,而非在原地址进行修改。String被
final修饰,不可继承,实例化后不能被修改。其本质上是一个final修饰的字符数组char[]。final修饰的叫不可变类,一旦对象创建在内存中就不可变。String是线程安全的,因为string内部存储字符串的char数组以及和char数组相关的信息都是final的。StringBuilder虽然也被
final修饰,但其底层的char数组并非final(定义在其父类AbstractStringBuilder中),是一个可以被修改的动态数组。所有方法没有被synchronized修饰,并非线程安全。StringBuffer也被
final修饰,但其线程安全,因为里面所有方法都被synchronized修饰。
KMP
https://www.cnblogs.com/SYCstudio/p/7194315.html
HashMap内部结构,调用put方法时如何实现,红黑树
参考博客
https://www.cnblogs.com/shipengzhi/articles/2087505.html
https://www.cnblogs.com/wang-meng/p/9b6c35c4b2ef7e5b398db9211733292d.html
https://blog.csdn.net/sinat_37906153/article/details/83004831
https://www.cnblogs.com/yuanblog/p/4441017.html
https://blog.csdn.net/u013164931/article/details/81389314
存储形式
在HashMap中 存储key-value时,所有的计算都是 基于Entry中 的key,没有考虑value,可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可。存储形式仍然是Entry<key,value>.
HashMap的规则
HashMap中,键和值都可以为null(null键只能有一个)
HashMap 的初始长度为 16,且每次扩容都必须以 2 的倍数(2^n)扩充,这是由取模规则
hashCode & (length - 1)决定的。 加载因子默认为0.75,size超过capacity的0.75 倍便2倍扩充。如果两个Entry的key的hashCode()返回值相同,那它们的存储位置相同(因为取模之后的值肯定相同啦)。如果这两个Entry的key通过equals比较返回true,新添加 Entry 的 value 将覆盖集合中原有 Entry的 value,但key不会覆盖。如果这两个 Entry 的 key 通过 equals 比较返回 false,新添加的 Entry 将添加到Entry 链的头部。
jdk1.8:当hash冲突元素达到8个后将链表转换为红黑树,在元素个数小于 6 时还原成链表
jdk1.8:元素的hashCode() 在很多时候下低位是相同的,这将导致冲突(碰撞),因此 1.8 以后做了个移位操作:将元素的 hashCode() 和自己右移 16 位后的结果求异或。将 hashCode 的高位和低位混合起来,降低冲突概率。
我们将 hashCode 值右移 16 位,也就是取 int 类型的一半,刚好将该二进制数对半切开。并且使用位异或运算,简而言之就是尽量打乱hashCode的低16位,因为真正参与运算的还是低16位。
put方法
对key取hash运算后,所得hashcode对数组大小取模,得到元素在数组中的位置(即下标),若此位置已经有了其他元素,则将元素插入到链头;若没有元素则直接放到数组该位置上。
因为有了取模的运算,所以链表中的元素存在一起并不都是哈希冲突造成的。
此处的取模运算是hashCode & (length - 1),length为数组的capacity。利用位运算代替取模运算,可以大大提高程序的计算效率。位运算可以直接对内存数据进行操作,不需要转换成十进制,因此效率要高得多。
需要注意的是,只有在特定情况下,位运算才可以转换成取模运算(当 b = 2^n 时,a % b = a & (b - 1) )。也是因此,HashMap 才将初始长度设置为 16,且扩容只能是以 2 的倍数(2^n)扩容
get方法
从HashMap中get元素时,首先计算key的hashCode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。
面试手写get与put方法
ConcurrentHashMap的原理
HashSet是如何保证元素不重复的
MySQL中插入一千万条数据如何是实现,在一亿条账号中查找有没有你的账号,找到重复的账号
String,StringBuffer,StringBuilder
数组(Array)和列表(ArrayList)的区别?什么时候应该使用Array而不是ArrayList?
hashCode与equals
https://www.cnblogs.com/yuanblog/p/4441017.html
如果两个对象相同,就是适用于equals(java.lang.Object) 方法,那么这两个对象的hashCode一定要相同
如果对象的equals方法被重写,那么对象的hashCode也尽量重写,并且产生hashCode使用的对象,一定要和equals方法中使用的一致,否则就会违反上面提到的第2点
迭代器,枚举
HashMap, HashTable, ConcurrentHashMap
线程池
乐观锁与悲观锁
读写锁的优先级
JVM
有三个比较容易混淆的概念:
Java内存模型(Java Memory Model(JMM))
JVM内存结构(JVM内存分区)
Java对象结构
GC
NIO,AIO,BIO,多路复用
死锁与解锁
Redis
http://www.runoob.com/redis/redis-tutorial.html
数据库的数据结构,索引
transient与序列化
反射
拦截器和过滤器
红黑树 b树 b+树 区别
cpu密集型 io密集型
线程池设计(很详细)
链表按段翻转
http https
线程间通信,进程间通信
线程间通信
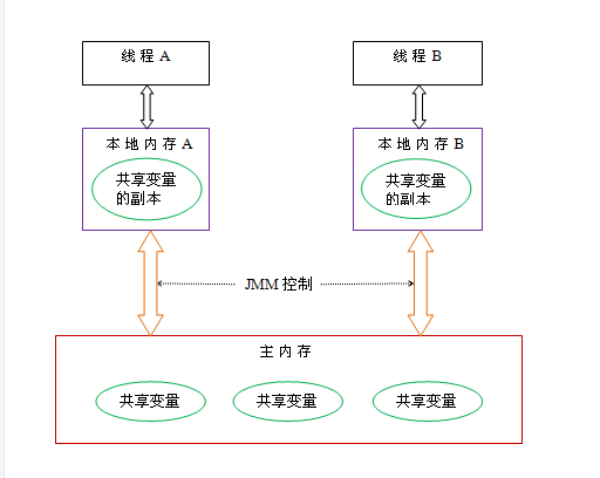
此处参考书籍《Java并发编程的艺术》Page 22
共享变量包括了堆内存中的实例域,静态域和数组元素,堆内存在线程之间共享。
局部变量,方法定义参数,异常处理参数不在线程之间共享, 不存在内存可见性,也不受内存模型影响。
线程间的通信由Java内存模型JMM控制,线程间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本次内存中存储该线程用于读/写的共享变量的副本。每个线程不能访问其他线程的本地内存。本地内存是抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及硬件和编译器优化。
线程A、B之间通讯必须经过两个步骤
① 线程A把本地内存A中更新过的共享变量刷新到主内存;
② 线程B到主内存中读取线程A之前更新过的共享变量。
手写工厂模式
spring bean的生命周期
哈夫曼树的带权路径长度
添加非聚集索引
Floyd算法
链表反转
秒杀系统
数据库索引的实现,数据库的数据结构
哪些对象可以作为GC Roots,它们有什么共同点吗?
cap,分布式锁
sql调优
gc收集器
设计模式
类加载器
字典树,大数计算
手写二分法
SpringAop 的实现原理
千万级数据如何查找
双亲委派加载,双亲委派的破坏
jvm的oom如何解决
数据库引擎
很大的数据量几个G,怎么找出前10大的(用一个最小堆保存,遍历一遍)
两个栈实现队列
i++如何实现原子操作
Java的四种引 用?
强引用 弱引用 虚引用 软引用
ArrayList和vector的区别
滑动窗口
tcp滑动窗口
超时重传,多路复用,拥塞控制
找到两个存放了1亿多字符串的文件的相同的字符串
最大上升子序列,动态规划
枚举
线程池参数及其含义
JVM。主要问CMS与G1,问得很细。
比如:CMS工作时,具体怎么标记对象是否可达的。假如现在CMS在进行垃圾收集了,同时用户线程又在工作,会有新的对象分配,那么CMS能否感知到用户线程是否产生了垃圾,本次垃圾收集时候,如何避免回收掉用户产生的新对象